Claude 4.5 Sonnet vs Claude 4.1 Opus
Compare Claude 4.5 Sonnet and Claude 4.1 Opus. Find out which one is better for your use case.
Model Comparison
| Feature | Claude 4.5 Sonnet | Claude 4.1 Opus |
|---|---|---|
| Provider | Anthropic | Anthropic |
| Model Type | text | text |
| Context Window | 1,000,000 tokens | 1,000,000 tokens |
| Input Cost | $3.00 / 1M tokens | $15.00 / 1M tokens |
| Output Cost | $15.00 / 1M tokens | $75.00 / 1M tokens |
Strengths & Best Use Cases
Claude 4.5 Sonnet
1. Best-in-class coding performance
- #1 on SWE-bench Verified (77.2% standard, 82.0% high-compute).
- Excels at debugging, architecture, and multi-file code generation.
- Maintains coherence for extremely long tasks (30+ hours).
2. State-of-the-art computer use & agents
- Leads OSWorld at 61.4%.
- Strongest model for agentic workflows, multi-step tool use, and real computer control.
- Powering Claude Code, the new Claude Agent SDK, and Chrome agent actions.
3. Advanced reasoning & math
- Large improvements across reasoning-heavy benchmarks (AIME, MMMLU, τ2-bench, Terminal-Bench).
- Deep multi-step reasoning with extended or interleaved thinking.
4. High alignment & safety
- Most aligned Claude model to date with reduced deception, hallucinations, sycophancy, and harmful compliance.
- Strong protections against prompt injection for agentic tasks (ASL-3 safeguards).
5. Domain-expert performance
- Notable gains in finance, law, medicine, and STEM tasks.
- Trusted by early customers for long-context legal analysis, multi-file engineering, security research, and red-teaming.
Claude 4.1 Opus
1. Advanced Coding Performance
-
Achieves 74.5% on SWE-bench Verified, improving the Claude family's state-of-the-art coding abilities.
-
Stronger at:
- Multi-file code refactoring
- Large codebase debugging
- Pinpointing exact corrections without unnecessary edits
-
Outperforms Opus 4 and shows gains comparable to jumps seen in past major releases.
2. Improved Agentic & Research Capabilities
- Better at maintaining detail accuracy in long research tasks.
- Enhanced agentic search and step-by-step problem solving.
- Performs reliably across complex multi-turn reasoning tasks.
3. Validated by Real-World Users
- GitHub: Better multi-file refactoring and code adjustments.
- Rakuten Group: High precision debugging with minimal collateral changes.
- Windsurf: One standard deviation improvement on their junior dev benchmark—similar magnitude to Sonnet 3.7 → Sonnet 4.
4. Hybrid-Reasoning Benchmark Improvements
- Improvements across TAU-bench, GPQA Diamond, MMMLU, MMMU, AIME (with extended thinking).
- Stronger robustness in long-context reasoning tasks.
Turn your AI ideas into AI products with the right AI model
Appaca is the complete platform for building AI agents, automations, and customer-facing interfaces. No coding required.
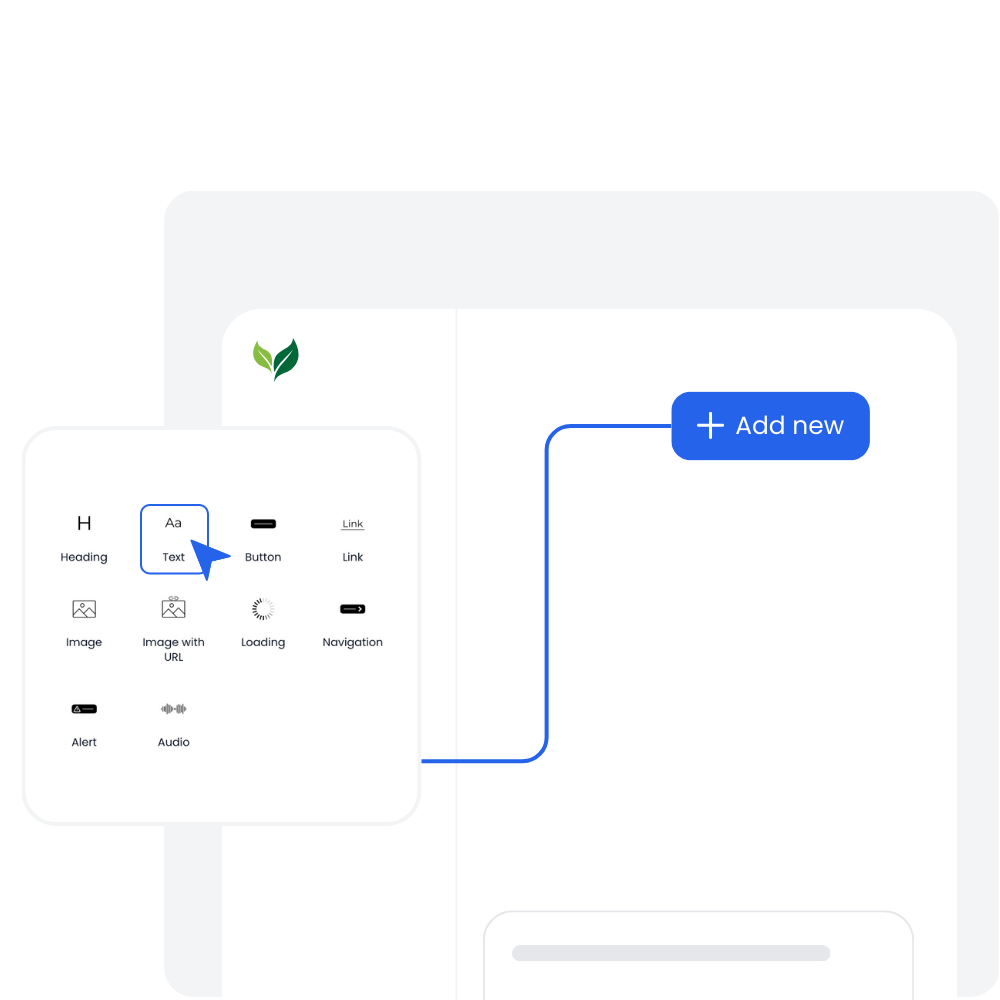
Customer-facing Interface
Create and style user interfaces for your AI agents and tools easily according to your brand.

Multimodel LLMs
Create, manage, and deploy custom AI models for text, image, and audio - trained on your own knowledge base.
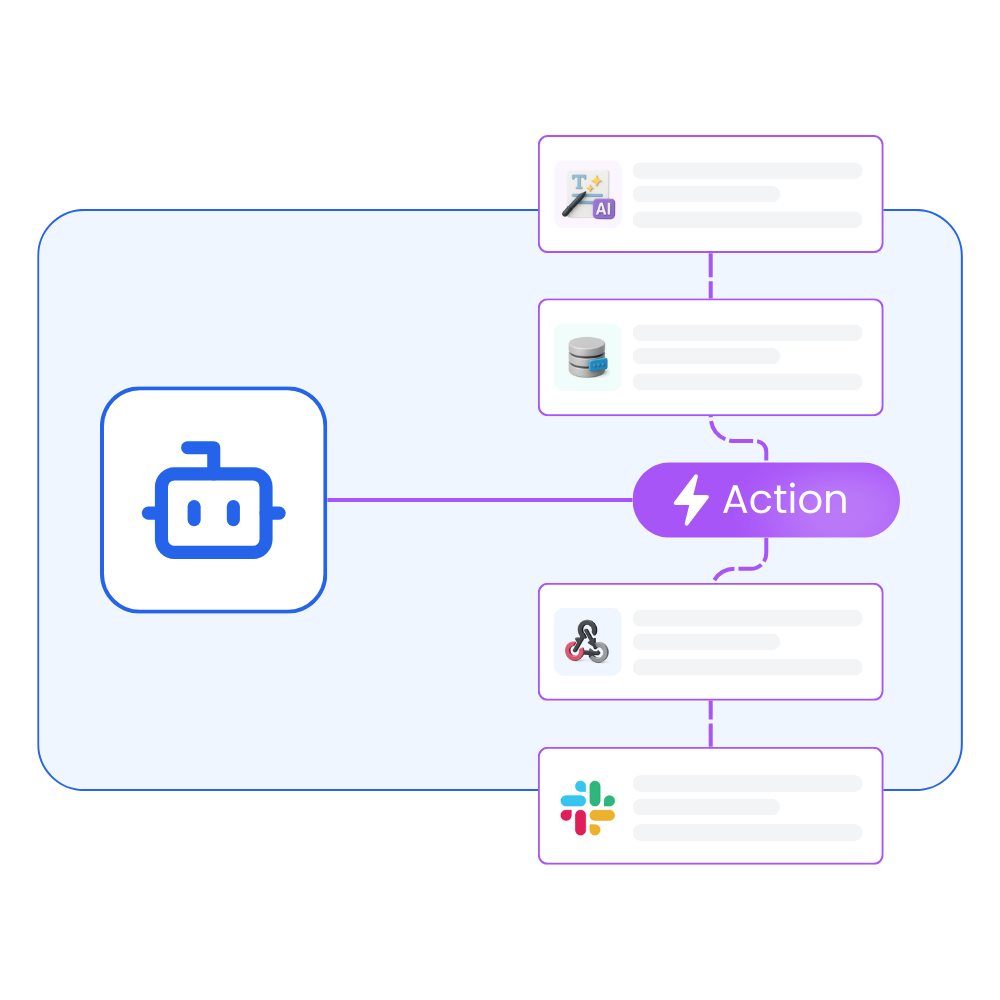
Agentic workflows and integrations
Create a workflow for your AI agents and tools to perform tasks and integrations with third-party services.
Trusted by incredible people at
All you need to launch and sell your AI products with the right AI model
Appaca provides out-of-the-box solutions your AI apps need.
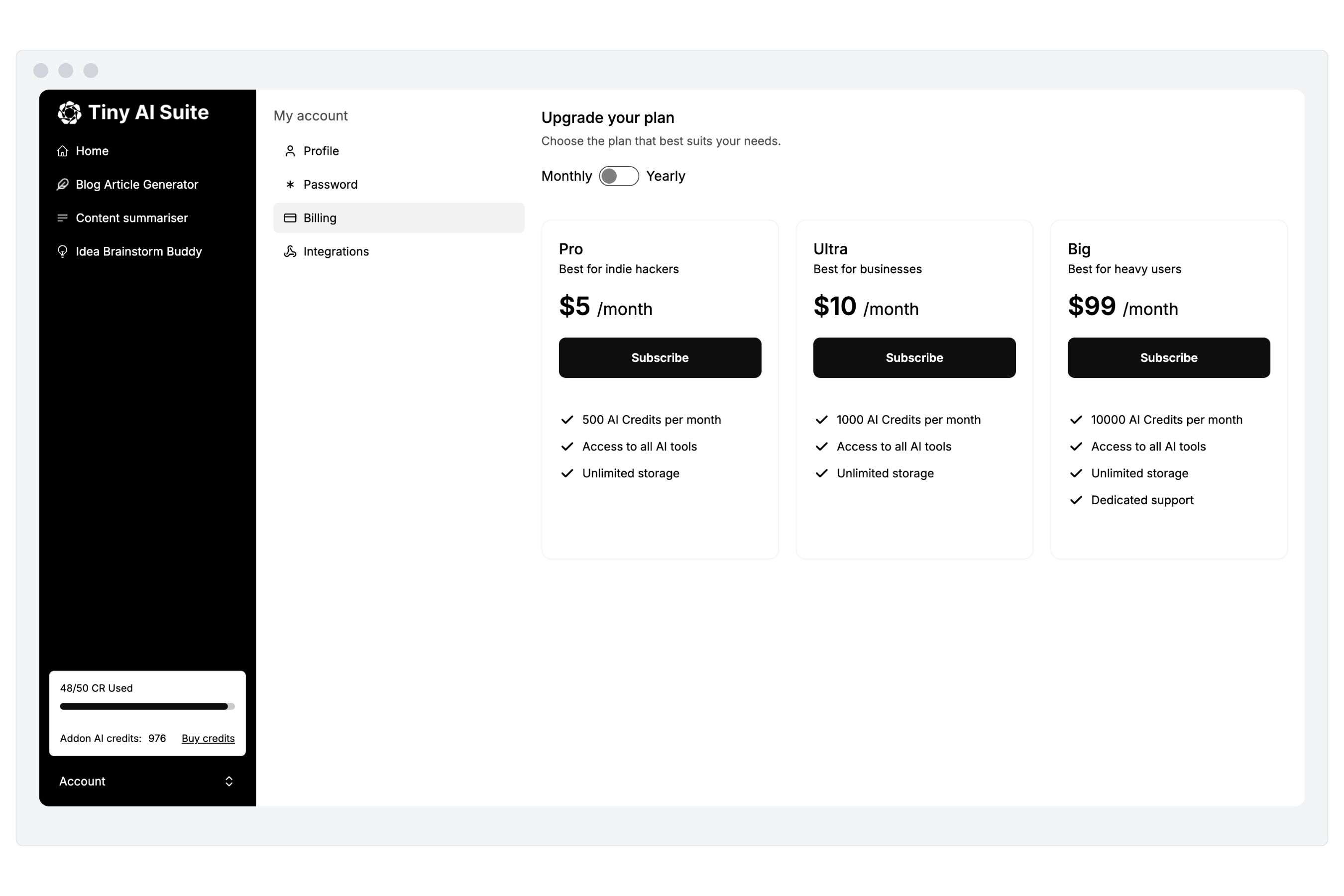
Monetize your AI
Sell your AI agents and tools as a complete product with subscription and AI credits billing. Generate revenue for your busienss.
“I've built with various AI tools and have found Appaca to be the most efficient and user-friendly solution.”

Cheyanne Carter
Founder & CEO, Edubuddy
Put your AI idea in front of your customers today
Use Appaca to build and launch your AI products in minutes.