AI Models Directory
Compare pricing, context windows, and strengths for 81 AI models from 7 providers - and see how teams put each one to work in Appaca, the no-code AI workspace.
OpenAI models
Frontier GPT models for reasoning, coding, and knowledge work, plus image generation and speech models - the most widely used AI model family for business workflows.
GPT-5.6 Sol
OpenAI's flagship model for complex professional work, combining frontier reasoning, coding, computer use, and long-horizon agentic performance with greater token efficiency.
GPT-5.5
OpenAI's smartest and most capable model yet for agentic coding, knowledge work, and computer use, delivering a new class of intelligence at GPT-5.4 latency.
GPT-5.4
OpenAI's frontier model for complex professional work with best intelligence at scale for agentic, coding, and professional workflows.
GPT-5.2
Previous frontier model for complex professional work with configurable reasoning effort.
GPT-5.1
Flagship model for coding, reasoning, and agentic tasks with adjustable reasoning depth and multimodal input/output.
GPT-5.3 Codex
Most capable agentic coding model to date, optimized for long-horizon software engineering tasks with configurable reasoning and multimodal input.
GPT-5.2 Codex
Highly capable coding model optimized for long-horizon, agentic coding tasks with configurable reasoning and strong codebase awareness.
GPT-5.1 Codex
Version of GPT-5.1 optimized for agentic coding inside Codex and similar environments, with strong reasoning and multimodal support.
Sora 2
Flagship video generation model that produces high-quality dynamic videos with synced audio from natural language or image prompts.
Sora 2 Pro
Most advanced video generation model with synced audio, producing highly detailed, dynamic clips from natural language or image inputs.
GPT-5
A high-reasoning model for coding and agentic tasks with configurable reasoning effort, supporting text + image input and large context windows.
GPT-5 Codex
Version of GPT-5 optimized for agentic coding tasks in Codex, offering strong reasoning, reliable code generation, and long-context project understanding.
GPT-5 Mini
A faster, cost-efficient version of GPT-5 designed for well-defined tasks, precise prompts, and high-speed execution with strong reasoning.
GPT-5 Nano
The fastest and cheapest GPT-5 variant, ideal for summarization, classification, and lightweight tasks requiring high speed and low cost.
GPT-5 Pro
A premium GPT-5 variant that uses more compute to deliver consistently smarter, more precise reasoning for the toughest problems.
GPT-4.1
A highly capable non-reasoning model that excels at instruction following, tool calling, and broad domain knowledge with a 1M-token context window.
GPT-4.1 Mini
Smaller, faster version of GPT-4.1 with low latency, strong instruction following, and a large 1M-token context window optimized for lightweight tasks.
GPT-4.1 Nano
Fastest and most cost-efficient GPT-4.1 model with strong instruction following, tool calling, and a 1M-token context window for lightweight, real-time tasks.
GPT-OSS 120B
OpenAI's most powerful open-weight model (117B params, 5.1B active), fitting on a single H100 GPU - fully customizable, licensed for unrestricted commercial use.
GPT-OSS 20B
A 21-billion-parameter open-weight model from OpenAI, designed for efficient reasoning and long-context usage (≈ 128K tokens).
GPT Image 1.5
State-of-the-art image generation model with improved instruction following and adherence to prompts.
GPT Image 1
State-of-the-art image generation model that accepts text and image inputs and produces high-quality images across multiple resolutions and quality levels.
GPT Image 1 Mini
A cost-efficient, multimodal image generation model that accepts text and image inputs and produces images across multiple resolutions and quality levels.
o4-mini
A fast, cost-efficient small reasoning model optimized for coding and visual tasks; succeeded by GPT-5 mini.
o3
A powerful reasoning model excelling at complex, multi-step tasks across math, science, coding, and visual reasoning; succeeded by GPT-5.
o3-mini
A small, cost-efficient reasoning model offering high intelligence at the same pricing and latency targets as o1-mini, with strong support for structured outputs and developer tooling.
o1
A full-size o-series reasoning model trained with RL to think before answering, producing strong multi-step reasoning across math, code, and analysis tasks.
o1-pro
A high-compute version of the o1 reasoning model, trained with reinforcement learning to think before answering and produce consistently stronger multi-step reasoning across math, science, coding, and analysis tasks.
GPT-4o
A versatile, high-intelligence flagship GPT model that handles text and image inputs and produces fast, high-quality text outputs for a wide range of tasks.
GPT-4o mini
A fast, affordable small model for focused tasks with multimodal input support and strong performance for classification, extraction, translation, and lightweight reasoning.
GPT-4o Audio
Preview multimodal model that accepts and outputs audio, optimized for natural voice interactions and real-time conversational experiences.
GPT-4o mini Audio
Fast, affordable audio-capable model for lightweight voice interactions, real-time responses, and low-cost speech-based applications.
GPT-4 Turbo
Older high-intelligence GPT-4 generation model offering strong reasoning and image input support, now superseded by newer 4o-based models.
GPT-3.5 Turbo
Legacy lightweight GPT model for cheap text generation and chat tasks; now replaced by faster, smarter, and cheaper 4o-mini models.
Google models
The Gemini family pairs strong reasoning with million-token context windows, alongside the Nano Banana models for fast, high-quality image generation.
Gemini 3.1 Pro
Google's most advanced reasoning Gemini model, built for complex multimodal problem-solving, software engineering, and long-horizon agentic workflows.
Nano Banana 2
High-efficiency native image model optimized for fast generation, editing, and conversational image workflows at high throughput.
Gemini 3 Pro
Google's most intelligent multimodal model designed for advanced reasoning, coding, and agentic tasks.
Nano Banana Pro
High-fidelity image model with precise controls, advanced text rendering, and world-knowledge grounding.
Gemini 2.5 Pro Experimental
Google's most advanced thinking model, leading benchmarks in reasoning, science, math, and coding with a massive multimodal context window.
Gemini 2.5 Flash
A fast, cost-efficient multimodal model optimized for everyday tasks with strong speed, long context, and native audio capabilities.
Nano Banana
High-quality, low-latency image model for generation, editing, fusion, and character consistency.
Gemini 1.5 Pro
A next-generation multimodal model with breakthrough long-context capability up to 1M tokens and strong reasoning across text, code, audio, video, and images.
Gemini 1.5 Flash
A fast, lightweight model optimized for low-latency, high-volume multimodal tasks with long-context support.
Gemini 1.0 Pro
A versatile multimodal model optimized for balanced performance across reasoning, language, and code tasks.
Anthropic models
Claude models are known for careful reasoning, long-document analysis, and dependable writing - a favourite for teams drafting reports, proposals, and policies.
Claude 5 Sonnet
Anthropic's most agentic Sonnet yet, closing much of the gap to Opus 4.8 on reasoning, coding, and tool use while staying at Sonnet's speed and price.
Claude 4.8 Opus
Anthropic's flagship model for coding and agents, building on Opus 4.7 with stronger reliability, a cheaper fast mode, and gains across coding, computer use, and professional work.
Claude 4.7 Opus
Anthropic's latest frontier Opus model, purpose-built for advanced software engineering, long-horizon agent work, and high-resolution multimodal reasoning.
Claude 4.6 Sonnet
Anthropic's most capable Sonnet model, delivering a full upgrade across coding, computer use, long-context reasoning, agent planning, and professional knowledge work.
Claude 4.5 Sonnet
A frontier-level hybrid-reasoning model excelling at coding, long-horizon tasks, computer use, and domain reasoning with top-tier alignment and reliability.
Claude 4.5 Haiku
A fast, small model delivering near-frontier coding and computer-use performance at ultra-low cost with exceptional speed and strong safety.
Claude 4.6 Opus
Anthropic's most intelligent model for building agents and coding, with stronger reliability and precision for long-horizon engineering and enterprise workflows.
Claude 4.5 Opus
Anthropic's November 2025 flagship model, combining maximum capability with practical performance for coding, agents, computer use, and enterprise workflows.
Claude 4.1 Opus
A refined flagship model with improved coding, reasoning, research depth, and agentic task performance over Opus 4.
Claude 4 Sonnet
A balanced-hybrid reasoning model tuned for everyday assistant and high-volume tasks.
Claude 4 Opus
The flagship model, focused on deep reasoning, large-scale coding and sustained multi-step agentic workflows.
Claude 3.5 Sonnet
A fast, mid-tier model offering top-tier intelligence, strong reasoning, and advanced coding/vision capabilities at low cost.
Claude 3.5 Haiku
A fast, affordable model matching Claude 3 Opus on many tasks while delivering major improvements in coding, accuracy, and tool use.
Claude 3 Opus
The most intelligent Claude 3 model, built for highly complex reasoning, analysis, and open-ended problem solving across any domain.
Claude 3 Sonnet
Balanced model offering high intelligence with fast performance, excellent for scalable enterprise workloads and real-time responses.
Claude 3 Haiku
Ultra-fast, cost-efficient model built for real-time interactions, instant responses, and high-volume workloads.
xAI models
Grok models combine strong reasoning with up-to-date knowledge, built for fast-moving research and analysis tasks.
Grok 4
A flagship multimodal model excelling in natural language, math, and deep reasoning with unmatched all-around performance.
Grok 3
A high-performance enterprise model for coding, extraction, reasoning, and domain-expert tasks across finance, healthcare, law, and science.
Grok 3 Mini
A lightweight reasoning model that is fast, efficient, and ideal for logic-heavy tasks without deep domain requirements.
Alibaba Cloud models
The Qwen family spans flagship reasoning models, fast and affordable workhorses, and omni models that handle text, image, and audio together.
Qwen3-Max
Top-tier Qwen3 model for complex, multi-step reasoning and agent workflows.
Qwen-Max
High-performance general-purpose Qwen model with strong coding and reasoning abilities.
Qwen-Plus
Balanced Qwen model with strong speed, cost efficiency, and optional reasoning mode.
Qwen3-Plus
Improved Qwen3 generation of Plus model with better reasoning, tool use, and alignment.
Qwen-Flash
The fastest and cheapest Qwen model, ideal for high-volume workloads.
Qwen3-Flash
Upgraded Flash model with improved capabilities and hybrid reasoning support.
Qwen-Turbo
Fast, low-cost model for general tasks; being phased out in favor of Flash.
QwQ-Plus
A reasoning-optimized model built on Qwen2.5 with strong math and code performance.
Qwen-Long
Long-context model with 10M tokens for huge document analysis and summarization.
Qwen-Omni-Turbo
Multimodal turbo model supporting text, image, audio, and video with fast output.
Qwen3-Omni-Flash
Hybrid thinking multimodal model with upgraded vision, audio, and agent abilities.
Qwen3-Omni-Flash-Realtime
Real-time multimodal model with streaming audio input and VAD for live use.
QVQ-Max
High-end visual reasoning model with strong math, coding, and diagram understanding.
Qwen3-VL-Plus
Text-generation model with strong vision understanding, OCR, reasoning, and summaries.
Meta models
Open-weight Llama models that deliver solid general-purpose performance with the flexibility of open licensing.
DeepSeek models
Open-weight reasoning and chat models that punch far above their price point - ideal for high-volume tasks where cost matters.
DeepSeek V3
A data-analysis powerhouse built for large-scale pattern recognition, prediction, and working with massive datasets.
DeepSeek R1
A fast, real-time decision-making model optimized for rapid analysis, dynamic adjustments, and responsive AI behavior.
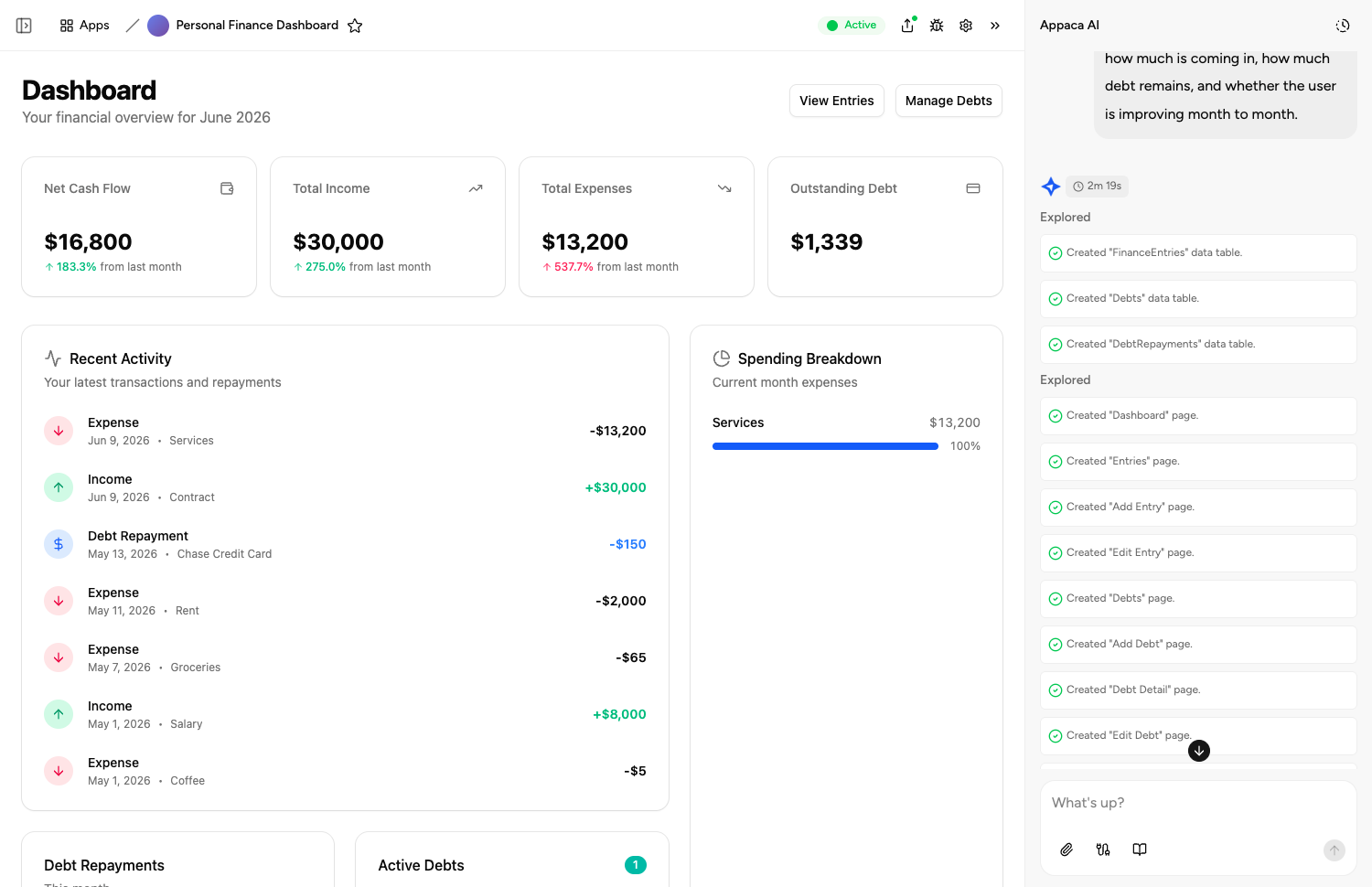
Put any of these models to work
Appaca is the AI workspace for operators. Build internal tools and AI co-workers powered by any model in this directory - connected to your real data and ready for your whole team.
Describe it, and it's built
Tell the Appaca agent the internal tool you need - a lead scorer on Claude, a report generator on GPT-5.5, an image tool on Nano Banana - and it builds a working app. No code, no API keys, no deployment.
Connected to your real data
Connect Slack, Notion, Google Sheets, Airtable, and more, plus a built-in database - so every model works with your team's real context instead of generic answers.
Automated for the whole team
Schedule tools to run on autopilot - daily digests, weekly reports, real-time triggers - and share them with your whole team from one workspace.
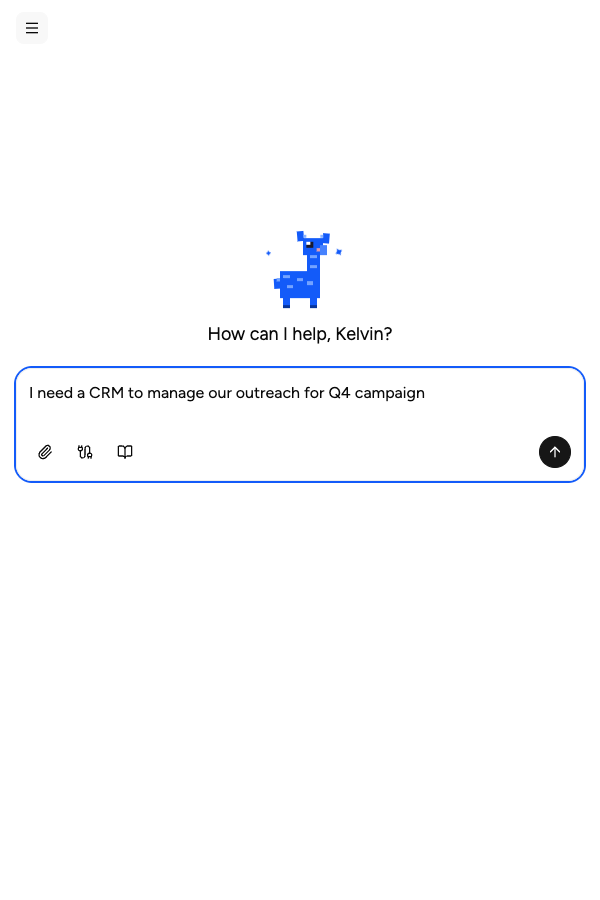
Describe it, and it's built
Tell the Appaca agent what your team needs and it builds a working app powered by the model you choose - connected to the tools you already use.









Where teams use these models
See how every team uses AI models inside Appaca - internal tools and AI agents that work around you.
Sales
Score leads, draft follow-ups, and generate proposals with the model that fits each job.
Explore Appaca for SalesFinance
Extract invoice data, chase payments, and write monthly summaries automatically.
Explore Appaca for FinanceMarketing
Draft and repurpose content in your brand voice, and generate campaign visuals on demand.
Explore Appaca for MarketingHR
Write job descriptions, answer policy questions, and build onboarding plans in minutes.
Explore Appaca for HROperations
Automate reporting, vendor tracking, and SOP answers with AI built around your process.
Explore Appaca for OperationsProduct Engineering
Draft PRDs, synthesise customer feedback, and triage bugs with frontier reasoning models.
Explore Appaca for Product EngineeringIT Support
Deflect tier-1 tickets with bots that answer instantly from your own documentation.
Explore Appaca for IT SupportFAQs
It depends on the job. Frontier models like GPT-5.5, Gemini 3.1 Pro, and Claude 4.7 Opus handle complex reasoning and long documents. Fast, low-cost models like Gemini Flash, Claude Haiku, and DeepSeek V3 suit high-volume tasks. Image models like Nano Banana generate visuals. In Appaca, you can pick a different model for each tool - and switch later without rebuilding anything.
Most text models charge per token - separate rates per million input and output tokens. Image models charge per generated image, usually varying by resolution and quality. Open-weight models like Llama and DeepSeek can be run without per-token licensing fees. Each model page in this directory lists its current pricing and context window.
Yes. Appaca is a no-code AI workspace: describe the internal tool your team needs and the Appaca agent builds it as a working app powered by the model you choose - with a built-in database, team access, and integrations. No API keys to wire up and nothing to deploy.
The context window is how much text a model can consider at once, measured in tokens. A larger context window - like Gemini's 1M tokens - means the model can work across entire codebases, long contracts, or months of records in a single pass without losing track.
Appaca is an AI workspace for operators. Describe what your team needs and get a working app with a built-in database, team access, and no coding or deployment required. It supports the AI models in this directory, so your tools always run on the model that fits the task.
Build AI agents and tools that use any AI model
Describe the tool your team needs and get a working app powered by the right model - with a built-in database, team access, and integrations. No code, no deployment.