GPT Image 1 Mini vs Gemini 1.5 Pro
Compare GPT Image 1 Mini and Gemini 1.5 Pro. Find out which one is better for your use case.
Model Comparison
| Feature | GPT Image 1 Mini | Gemini 1.5 Pro |
|---|---|---|
| Provider | OpenAI | |
| Model Type | image | text |
| Context Window | N/A | 1,000,000 tokens |
| Input Cost | $2.00 / 1M tokens | $3.50 / 1M tokens |
| Output Cost | N/A | $7.00 / 1M tokens |
Strengths & Best Use Cases
GPT Image 1 Mini
1. Cost-Efficient Image Generation
- A budget-friendly version of GPT Image 1 designed for high-volume or cost-sensitive workflows.
- Offers strong visual generation quality at significantly reduced per-image prices.
2. Natively Multimodal Architecture
- Accepts both text and image inputs, enabling:
- Image-to-image transformations
- Visual editing based on reference photos
- Enhanced control via mixed inputs
- Outputs high-quality images aligned with the prompt or reference.
3. Flexible Resolution & Quality Options
- Supports three quality tiers (Low, Medium, High).
- Available in multiple resolutions:
- 1024x1024
- 1024x1536
- 1536x1024
- Allows users to choose between affordability and visual detail.
4. Practical for Real-World Applications Ideal for:
- Marketing visuals
- UI/UX mockups
- Concept art
- Prototyping & brainstorming
- Lightweight creative tools within SaaS platforms
5. Broad API Integration Works across all major endpoints:
- Chat Completions
- Responses
- Realtime
- Assistants
- Image generation & image edits
- Batch and embedding pipelines for more complex workflows.
6. Streamlined Feature Set for Simplicity
- No streaming, function calling, structured output, or fine-tuning.
- Focused exclusively on reliable, easy-to-use image generation.
7. Snapshot Support for Consistency
- Supports stable snapshots so developers can lock behavior and ensure reproducible outputs across deployments.
Gemini 1.5 Pro
1. Breakthrough long-context window up to 1,000,000 tokens
- Can process 1 hour of video, 11 hours of audio, 700k+ words, or 100k+ lines of code in a single prompt.
- Supports advanced retrieval, reasoning, summarization, and cross-document tasks.
- Achieves 99% retrieval accuracy on 1M-token Needle-In-A-Haystack tests.
2. Strong multimodal reasoning across video, audio, images, and text
- Can analyze long videos (e.g., full silent films), track events, infer causality, and identify small details.
- Handles large complex documents like manuals, transcripts, and books.
3. High-performance reasoning and problem solving
- Comparable to Gemini 1.0 Ultra across many benchmarks.
- Excels at code reasoning, multi-step explanations, and large-scale codebase analysis.
4. Advanced code understanding and generation
- Performs problem-solving on codebases exceeding 100,000 lines.
- Capable of cross-file reasoning, debugging guidance, API comprehension, and generating structured code improvements.
5. Efficient Mixture-of-Experts (MoE) architecture
- Activates only relevant expert pathways per input.
- Enables faster training, lower latency, and more efficient serving.
- Dramatically improves scalability and inference speed.
6. Exceptional in-context learning capabilities
- Learns new tasks directly from long prompts without fine-tuning.
- Demonstrated by learning to translate a low-resource language (Kalamang) from a grammar manual.
7. High-fidelity multimodal understanding
- Reads, analyzes, and reasons about long PDFs, code repositories, images, and videos together.
- Enables new classes of applications: legal analysis, scientific review, codebase audits, long-form content generation, etc.
8. Safety and reliability first
- Undergoes extensive ethics, safety testing, and red-teaming.
- Improved representational safety and reduced hallucinations compared to previous generations.
9. Available for developers and enterprises
- Accessible via AI Studio and Vertex AI.
- Supports future pricing tiers for expanded context windows.
- Designed for real enterprise-scale workloads.
10. Widely capable mid-size model
- Positioned between Gemini Pro and Gemini Ultra generations.
- Well-balanced: reasoning, multimodality, long-context, and speed.
Turn your AI ideas into AI products with the right AI model
Appaca is the complete platform for building AI agents, automations, and customer-facing interfaces. No coding required.
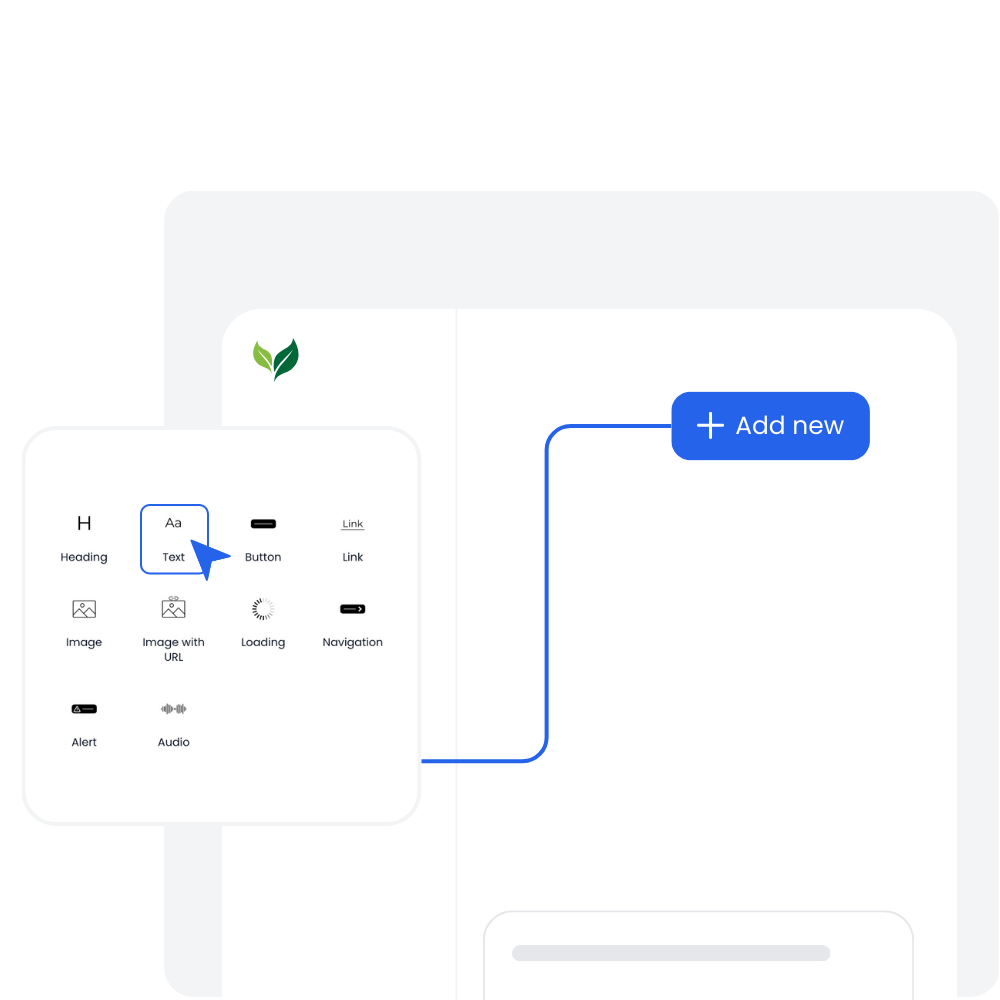
Customer-facing Interface
Create and style user interfaces for your AI agents and tools easily according to your brand.

Multimodel LLMs
Create, manage, and deploy custom AI models for text, image, and audio - trained on your own knowledge base.
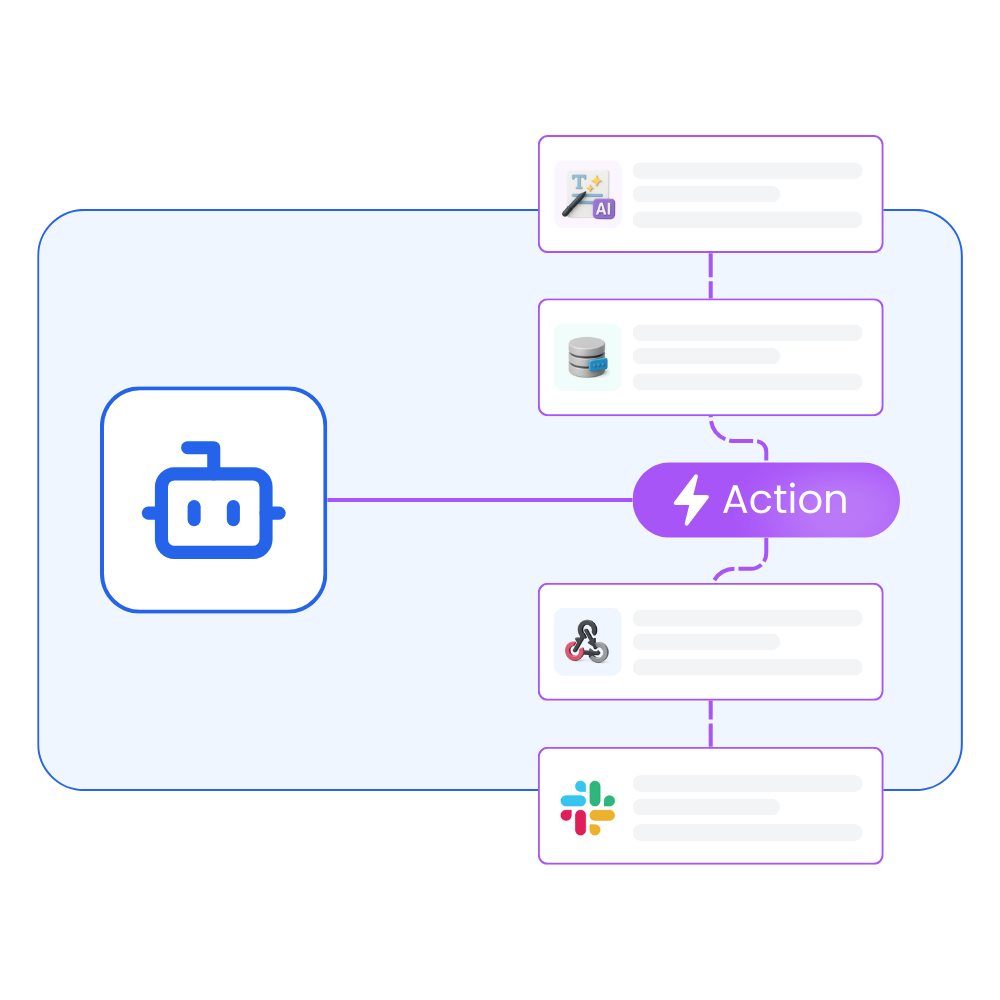
Agentic workflows and integrations
Create a workflow for your AI agents and tools to perform tasks and integrations with third-party services.
Trusted by incredible people at
All you need to launch and sell your AI products with the right AI model
Appaca provides out-of-the-box solutions your AI apps need.
Monetize your AI
Sell your AI agents and tools as a complete product with subscription and AI credits billing. Generate revenue for your busienss.
“I've built with various AI tools and have found Appaca to be the most efficient and user-friendly solution.”

Cheyanne Carter
Founder & CEO, Edubuddy
Put your AI idea in front of your customers today
Use Appaca to build and launch your AI products in minutes.