Best AI Models for Research
Research applications push LLMs to their limits - requiring synthesis across multiple long documents, careful reasoning about conflicting evidence, and structured output that meets academic standards. Context window size and factual accuracy are the two most critical factors: a model that summarises confidently but incorrectly is actively harmful in a research context.
Top AI models for Research
Ranked by real-world performance on research tasks - pricing, context windows, and strengths for each.
GPT-5.5
text 1M tokens contextOpenAI's smartest and most capable model yet for agentic coding, knowledge work, and computer use, delivering a new class of intelligence at GPT-5.4 latency.
Claude 4 Opus
text 200K tokens contextThe flagship model, focused on deep reasoning, large-scale coding and sustained multi-step agentic workflows.
GPT-5.4
text 1.1M tokens contextOpenAI's frontier model for complex professional work with best intelligence at scale for agentic, coding, and professional workflows.
Claude 4 Sonnet
text 1M tokens contextA balanced-hybrid reasoning model tuned for everyday assistant and high-volume tasks.
Evaluation criteria for Research
The four factors that matter most when choosing an AI model for research tasks.
Depth and accuracy of scientific reasoning
Ability to synthesise multi-document context
Citation awareness and factual grounding
Structured output for reports and papers
Compare top Research models
Side-by-side pricing, specs, and strengths for every pair of top research models.
GPT-5.5 vs Claude 4 Opus
OpenAI vs Anthropic for research - pricing, context windows, and strengths compared.
See the comparisonGPT-5.5 vs GPT-5.4
OpenAI vs OpenAI for research - pricing, context windows, and strengths compared.
See the comparisonGPT-5.5 vs Claude 4 Sonnet
OpenAI vs Anthropic for research - pricing, context windows, and strengths compared.
See the comparisonGPT-5.4 vs Claude 4 Opus
OpenAI vs Anthropic for research - pricing, context windows, and strengths compared.
See the comparisonClaude 4 Sonnet vs Claude 4 Opus
Anthropic vs Anthropic for research - pricing, context windows, and strengths compared.
See the comparisonGPT-5.4 vs Claude 4 Sonnet
OpenAI vs Anthropic for research - pricing, context windows, and strengths compared.
See the comparisonBuild Research tools with the right model
Appaca is the AI workspace for operators. Build internal tools and AI co-workers powered by any of these models - connected to your real data and ready for your whole team. No code, no deployment.
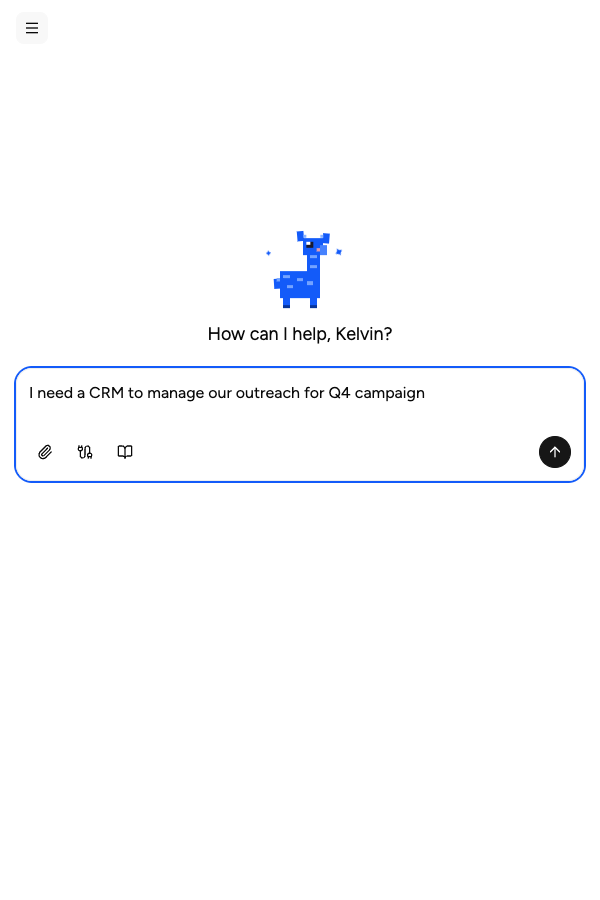
Build research tools instantly
Tell the Appaca agent the internal tool you need and it builds a working app powered by the model you choose for research. No code, no API keys, no deployment.
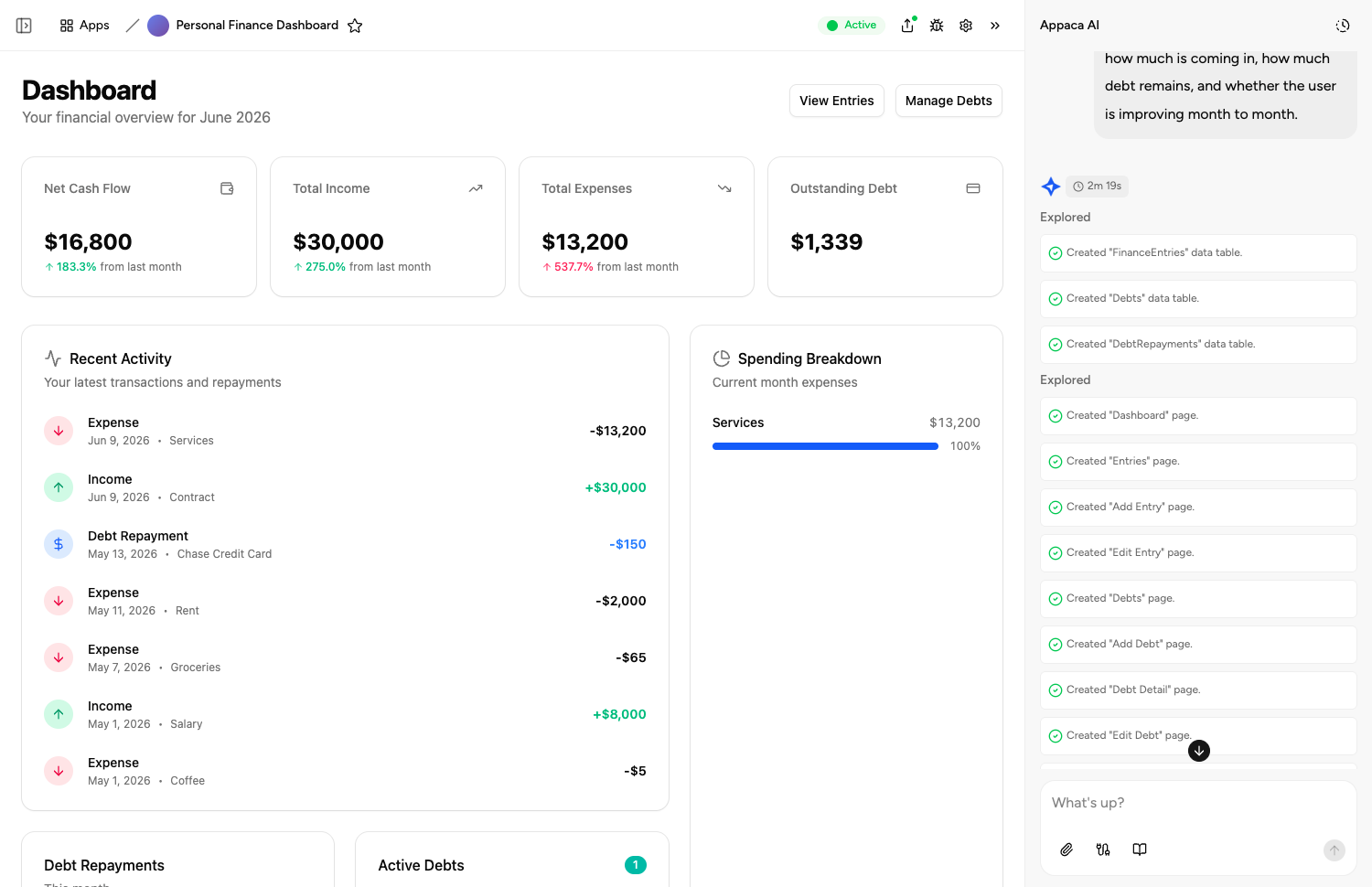
Connected to your real data
Connect Slack, Notion, Google Sheets, Airtable, and more, plus a built-in database - so your AI tools work with your team's real context instead of generic answers.
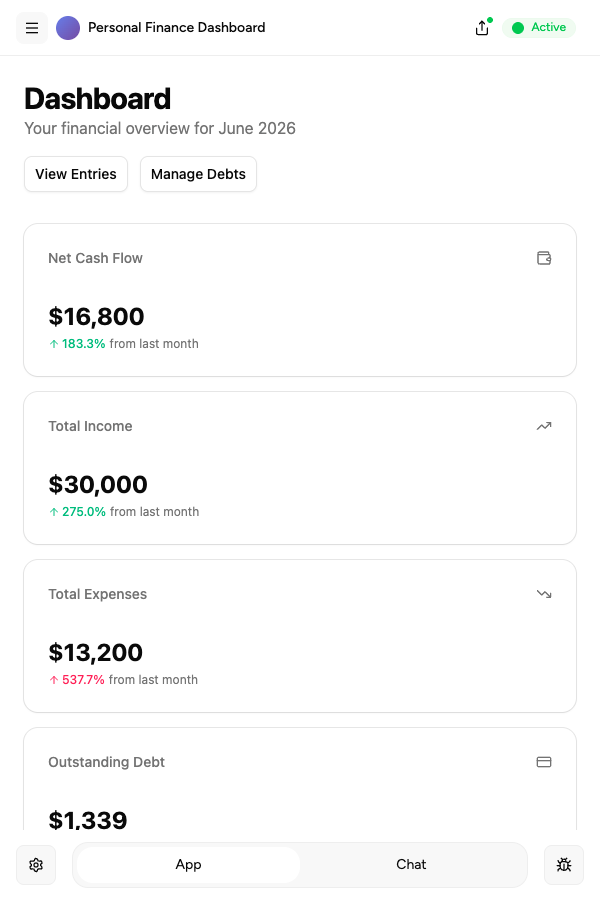
Automated for the whole team
Schedule tools to run on autopilot - daily digests, weekly reports, real-time triggers - and share them with your whole team from one workspace.
Describe it, and it's built
Tell the Appaca agent what your team needs and it builds a working app powered by the model you choose - connected to the tools you already use.









Explore more use cases
Top-ranked AI models for other common business tasks.
FAQs
GPT-5.5 and Claude 4 Opus are the top research LLMs in 2026. GPT-5.5 produces well-structured research memos, literature summaries, and synthesis documents. Claude 4 Opus is preferred for tasks requiring careful reasoning about nuanced or contradictory evidence - it is more likely to flag uncertainty than state incorrect conclusions confidently. Gemini 2.5 Pro handles the longest source documents thanks to its 1M token context.
Yes, with appropriate source material provided. When given a set of papers or abstracts, LLMs can generate a structured literature review with thematic groupings, key findings, and gaps in the research. Provide the actual text of papers (not just titles) for best results. Always verify that the model has accurately attributed findings to the correct sources before including in any academic submission.
Gemini 2.5 Pro and Claude 4 Opus both offer 1M token context windows, enabling full-document analysis without chunking. For multi-paper synthesis where you need to compare findings across 10-20 papers simultaneously, Gemini 2.5 Pro is the strongest choice for maintaining coherence across the full context. Claude 4 Opus produces better written synthesis prose.
Both models have training cutoffs and can hallucinate citations. Claude 4 Opus is slightly more conservative - it is more likely to express uncertainty rather than fabricate an answer. GPT-5.5 is more likely to produce confident, well-structured output but should be checked for accuracy. For any research task, ground the model in your source documents using RAG rather than relying on model knowledge alone.
No - never use LLM-generated citations without independent verification. LLMs frequently hallucinate plausible-sounding but non-existent papers, authors, and DOIs. Use LLMs for structure, synthesis, and writing - but always source citations from verified databases like Google Scholar, PubMed, or Semantic Scholar. Consider using a tool with live search integration for current references.
Build AI tools for Research
Describe the research tool your team needs and get a working app powered by the right model - with a built-in database, team access, and integrations. No code, no deployment.